· 9 min read
Don’t Let Your AI Agent Forget: Smarter Strategies for Summarizing Message History
Explore effective strategies for summarizing message history in AI agents, ensuring they retain crucial context and information.
Copy a command, then paste it into the command palette (Ctrl K to open).
Introduction
A 1M token context window sounds like the end of forgetting, right? Just throw the whole conversation at the model and let it handle it. Not quite. Studies show that when you overload a model with massive prompts, performance actually drops. Bigger windows don’t automatically mean smarter agents.
If you’ve built an AI agent, you’ve probably seen this firsthand. At first it’s sharp and on-point, but as the dialogue grows, it starts to lose track, asking the same questions twice, forgetting earlier details, or drifting from the goal. That’s not a bug in your agent, it’s the cost of poor context management.
So the real question isn’t “how big is the window?” but “how do we feed the model only what it needs?” That’s where smarter history summarization comes in.
In this article, I’ll share strategies to keep your agents coherent, cost-efficient, fast and even when the context window is massive.
Core Context Management Strategies
Managing an agent's memory is a balancing act between context fidelity and token efficiency. Here are four primary approaches used today.
1. Rolling Summaries (Incremental Compression)
Imagine a conversation as a rolling snowball. Instead of letting it grow infinitely, you periodically melt it down, keeping its core shape and size manageable. This is the essence of a rolling summary.
After a certain number of messages (say, 5–10 turns), you use the LLM to create a concise summary of that conversational chunk. This summary then replaces the original messages in the history. The next summary will incorporate the previous summary and the new set of messages.
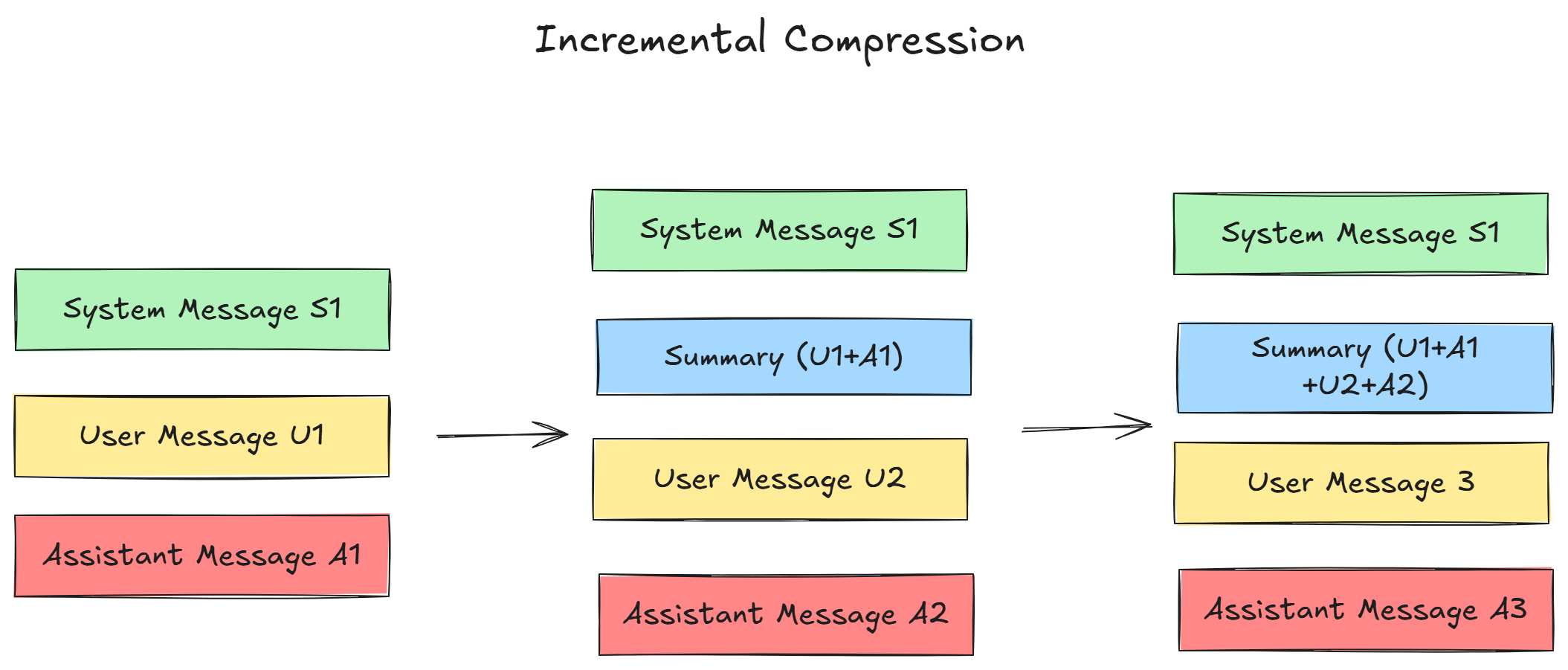
- Pros: Maintains a continuous, albeit compressed, thread of the entire conversation. Highly effective for long, evolving dialogues where the journey matters as much as the destination.
- Cons: Summarization is an imperfect process. Nuances, specific details, or subtle shifts in user intent can be lost in compression over time. It also adds a small amount of latency and cost for the summarization API calls.
2. Hybrid Memory (Keep Key Messages + Summaries)
This approach recognizes that not all messages are created equal. The very first message containing the user's core instruction or a critical piece of data from the middle of the conversation is far more important than simple conversational filler.
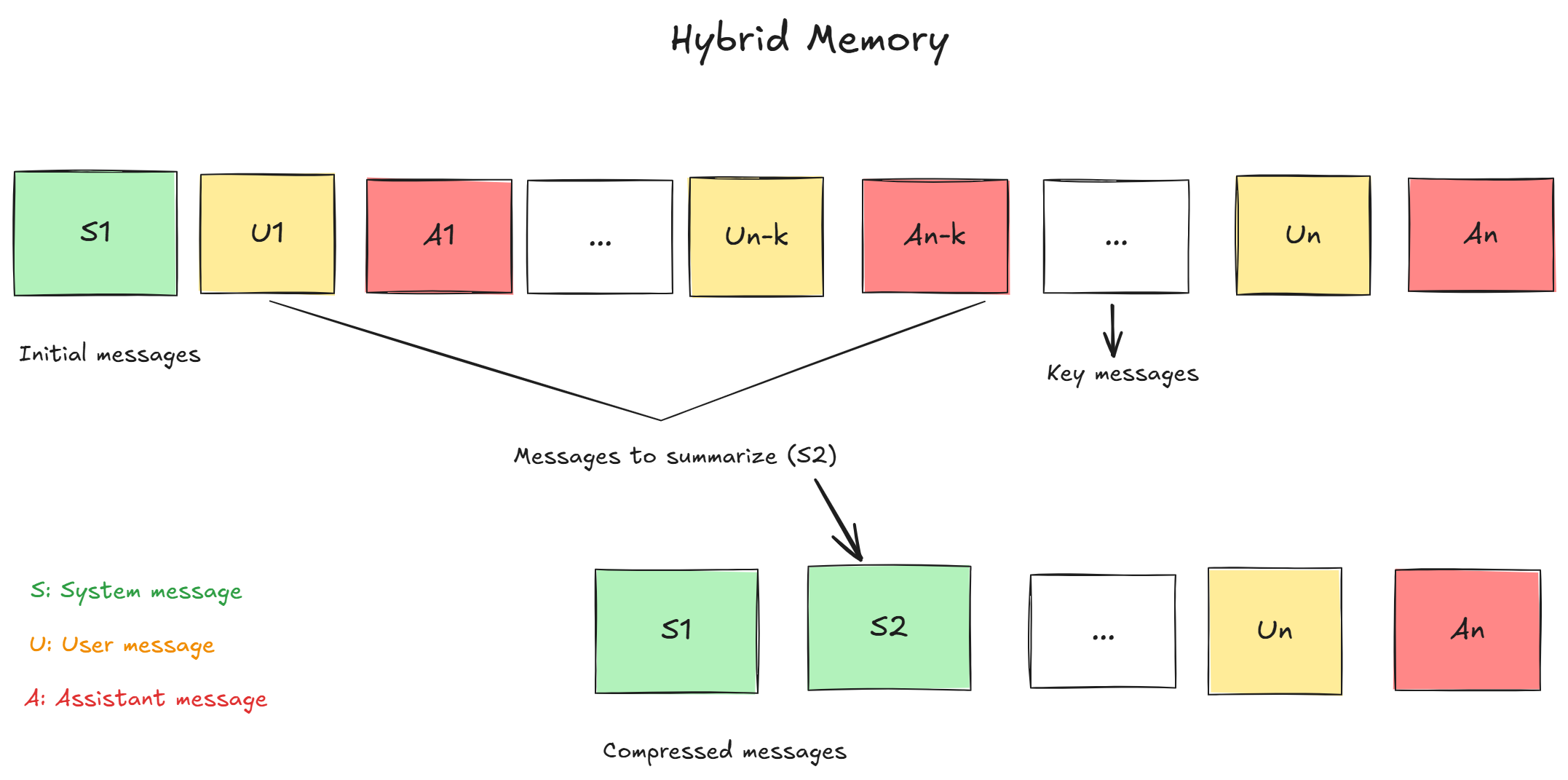
The hybrid strategy involves two components:
- A set of "pinned" or "key" messages: These are preserved in their original form. A common practice is to always keep the system prompt and the first user message.
- A summarized history: The messages between these key points are compressed using the rolling summary technique.
- Pros: Offers the best of both worlds—it preserves critical, high-fidelity information while compressing the less important conversational turns.
- Cons: The logic for determining which messages are "key" can be complex to implement and may not always be perfect.
3. Dynamic Cutoff (Token Budgeting)
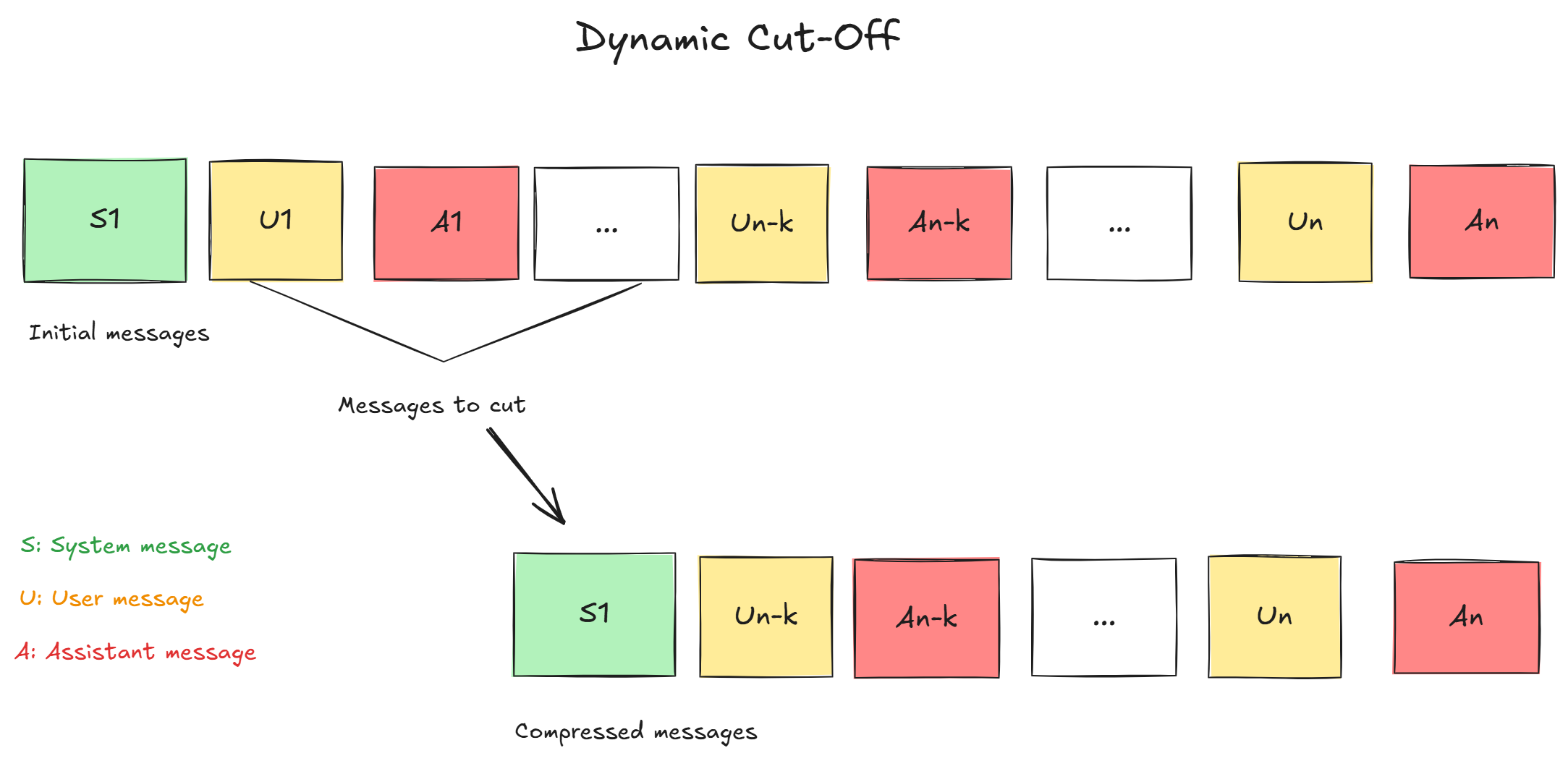
- Pros: Extremely simple and fast to implement. It requires no extra LLM calls for summarization.
- Cons: Context is lost abruptly. If a critical piece of information was mentioned 20 messages ago, the agent will have no memory of it, leading to a frustrating user experience.
4. Externalized Memory (DB/Vector Store)
For the most demanding applications, you can give your agent a long-term memory by connecting it to an external database. As the conversation progresses, key facts, user preferences, and summaries can be extracted and stored in a traditional database or a vector database.
When the agent needs to recall something, instead of just relying on its context window, it can query this external memory. Using a vector store for this allows for powerful "semantic search," where the agent can find relevant information based on meaning, not just keywords.
- Pros: Provides a near-infinite and persistent memory that can span multiple sessions. It's the most robust solution for building sophisticated, stateful agents.
- Cons: By far the most complex to set up and maintain. It introduces additional infrastructure, potential points of failure, and latency from database queries.
Practical Implementation with slimcontext and openai
Theory is great, but applying these strategies often involves writing a lot of repetitive, tricky boilerplate code to count tokens, slice arrays, and make intermediate API calls. This is where a dedicated library can be a lifesaver.
Let's look at slimcontext, a lightweight, zero-dependency NPM package designed to make message history management trivial. It elegantly implements a hybrid strategy, allowing you to set a token budget while ensuring key messages are never lost.
First, install the required packages in your Node.js project:
npm install slimcontext openai
Let’s put this into practice. Say your conversation history already exceeds your optimal context size—around 200 tokens, based on testing your agent. Your model has an 8K token limit, so the challenge is fitting in as much relevant context as possible without crossing that ceiling.
import {
SummarizeCompressor,
type SlimContextChatModel,
type SlimContextMessage,
type SlimContextModelResponse,
} from 'slimcontext'
import OpenAI from 'openai'
const client = new OpenAI() // assuming you have exported your OPENAI_API_KEY
class OpenAIModel implements SlimContextChatModel {
async invoke(msgs: SlimContextMessage[]): Promise<SlimContextModelResponse> {
const response = await client.chat.completions.create({
model: 'gpt-5-mini',
messages: msgs.map((m) => ({
role: m.role === 'human' ? 'user' : (m.role as 'system' | 'user' | 'assistant'),
content: m.content,
})),
})
return { content: response.choices?.[0]?.message?.content ?? '' }
}
}
async function main() {
const history: SlimContextMessage[] = [
{
role: 'system',
content:
"You are a helpful AI assistant. The user's name is Bob and he wants to plan a trip to Paris.",
},
{ role: 'user', content: 'Hi, can you help me plan a trip?' },
{ role: 'assistant', content: 'Of course, Bob! Where are you thinking of going?' },
{ role: 'user', content: 'I want to go to Paris.' },
{
role: 'assistant',
content: 'Great choice! Paris is a beautiful city. What do you want to do there?',
},
{ role: 'user', content: 'I want to visit the Eiffel Tower and the Louvre.' },
{
role: 'assistant',
content: 'Those are two must-see attractions! Do you have a preferred time to visit?',
},
{ role: 'user', content: 'I was thinking sometime in June.' },
{
role: 'assistant',
content: 'June is a great time to visit Paris! The weather is usually pleasant.',
},
{ role: 'user', content: 'What about flights?' },
{ role: 'assistant', content: 'I found some great flight options for you.' },
{ role: 'user', content: 'Can you show me the details?' },
{
role: 'assistant',
content:
'Here are the details for the flights I found:\n\n- Flight 1: Departing June 1st, 10:00 AM\n- Flight 2: Departing June 2nd, 2:00 PM\n- Flight 3: Departing June 3rd, 5:00 PM',
},
{
role: 'user',
content:
"I like the second flight option. I will check it out later, let's talk about hotels.",
},
{
role: 'assistant',
content:
'Some top hotel options in Paris include:\n\n- Le Meurice\n- Hôtel Plaza Athénée\n- Hôtel de Crillon',
},
// ...imagine 50 more messages here about flights, hotels, restaurants...
// This is our latest message
{ role: 'user', content: 'Okay, can you summarize the whole plan for me in a bulleted list?' },
]
const summarize = new SummarizeCompressor({
model: new OpenAIModel(),
maxModelTokens: 200, // Imagine this is the maximum token limit for your agent
thresholdPercent: 0.8,
minRecentMessages: 4, // The minimum number of recent messages you want to retain
})
const compressed = await summarize.compress(history)
console.log(compressed)
}
main()
When you run this code, the output might look something like this (look at the second message, it summarizes a portion of the conversation):
[
{
"role": "system",
"content": "You are a helpful AI assistant. The user's name is Bob and he wants to plan a trip to Paris."
},
{
"role": "system",
"content": "User (Bob) wants help planning a trip to Paris in June to visit the Eiffel Tower and the Louvre.\nAssistant confirmed June is a good time and reported finding flight options.\nUser asked the assistant to show the flight details."
},
{
"role": "assistant",
"content": "Here are the details for the flights I found:\n- Flight 1: Departing June 1st, 10:00 AM\n- Flight 2: Departing June 2nd, 2:00 PM\n- Flight 3: Departing June 3rd, 5:00 PM"
},
{
"role": "user",
"content": "I like the second flight option. I will check it out later, let's talk about hotels."
},
{
"role": "assistant",
"content": "Some top hotel options in Paris include:\n- Le Meurice\n- Hôtel Plaza Athénée\n- Hôtel de Crillon"
},
{
"role": "user",
"content": "Okay, can you summarize the whole plan for me in a bulleted list?"
}
]
As you can see, slimcontext intelligently handled the compression. It:
- Preserved the original system prompt (a key message).
- Summarized the intermediate messages into a single, concise context-setting message.
- Retained the most recent messages in full detail.
This gives the LLM the perfect blend of long-term context and short-term memory, all without the risk of exceeding its token limit. This just one strategy, you can check out others in the slimcontext documentation.
If you find slimcontext helpful for your own projects, please consider giving the repository a star on GitHub! ⭐ Your support is greatly appreciated. We're also actively looking for contributors, so if you have an idea for an improvement or a new feature, don't hesitate to open an issue or a pull request.
Conclusion
A long context window is not a long-term memory solution. As AI agents become more integrated into complex, multi-step workflows, intelligent and strategic context management is no longer a "nice-to-have"—it's a necessity.
By understanding the trade-offs between different approaches, from simple dynamic cut-offs to sophisticated externalized memories, you can choose the right strategy for your application. And with modern tools like slimcontext, implementing a robust hybrid memory system is no longer a daunting task. Don't let your agent's potential be limited by its memory; give it the tools it needs to remember, reason, and perform flawlessly over the long haul.
Further Reading
If you're interested in diving deeper into the topics covered in this article, here are some resources to check out: